按爬网付款信号是一种新的Web业务模型-为AI机器人收取访问权限炒股配资网站皆,并为内容创建者提供新的利润途径。
内容经济陷入困境。
AI爬行者读取网站,总结信息并提供答案,而无需向用户发送到原始来源。
结果?
AI模型的流量急剧下降,广告收入下降,以及对网络为数十年来推动的商业模式的日益增长的威胁。
现在,Cloudflare正在采用一种新方法。
就在两周前,首席执行官马修·普林斯(MatthewPrince)在接受Axios采访时说:
“AI将从根本上改变网络的业务模型。过去15年来网络的业务模型一直是搜索的。一种或另一种方式,搜索驱动所有发生在线发生的一切。
上周,CloudFlare引入了一个可能的解决方案:每次爬网付款,这是一个首先的货币化层,使出版商可以为AI机器人(例如OpenAI的GPTBOT或ANTHARPIC的Claudebot)收取用于访问其内容的费用。
这不是对网络工作原理的完整重新设计,而是在现有Web基础架构之上构建的新层。
该系统使用很少实施的HTTP402“必需付款”响应代码来阻止或收取试图爬网的机器人。
的未来意味着什么?那么,它如何工作,这对生成引擎优化(GEO)
让我们分解。
不言而喻的交易正在打破-这是第一次
那样,值得一会儿稍等片刻,以了解Cloudflare的举动背后的更深层次的背景。强调的正如Prince上周
大约30年前,两名斯坦福大学的学生开始从事一个名为“Backrub”的研究项目。
该项目成为Google。但这也变得更大:网络业务模型的基础。
Google和内容创作者之间的不言而喻的交易很简单:
让我们复制您的内容以在搜索结果中显示,作为回报,我们将向您发送流量。
作为创建者,您可以通过运行广告,出售订阅或只是享受阅读的满意度来获取流量。
Google构建了支持交易的整个生态系统:
Google搜索生成了流量。
Google购买了DoubleClick并推出了Adsense,以帮助您从中赚钱。
Google获取了Hilchin来创建GoogleAnalytics(分析),因此您可以测量所有内容。
它起作用。
几十年来,该协议一直使公开网络保持活力。
但是现在,这笔交易开始崩溃了。
首次Google的搜索市场份额正在下降,什么正在取代它们?
。
王子明确地说:
十年前,Google为发送给出版商的每个访客爬了两页。
六个月前,比率是:
Google:6:1
Openai:250:1
人类:6,000:1
今天:
Google:18:1
Openai:1,500:1
人类:60,000:1
趋势很明显:AI会读,学习和答案,但很少会寄回用户。
曾经为网络供电的相互价值交换正在悄悄崩溃,并且内容创建者被排除在方程式之外。
CloudFlare如何计划更改游戏
当您考虑一下时,解决方案实际上很聪明。
CloudFlare并没有强迫网站所有者在两个极端之间进行选择-完全阻止AI爬网或免费访问它们,而是引入了第三种选择:收费。
这是它的工作方式。
每次AI爬行者请求内容时,服务器都可以HTTP402付款(包括访问价格)进行响应。如果爬行者同意付款,它将发送带有付款标头的后续请求,并且服务器以200个确定的响应返回内容。如果没有,则不会授予访问权限。
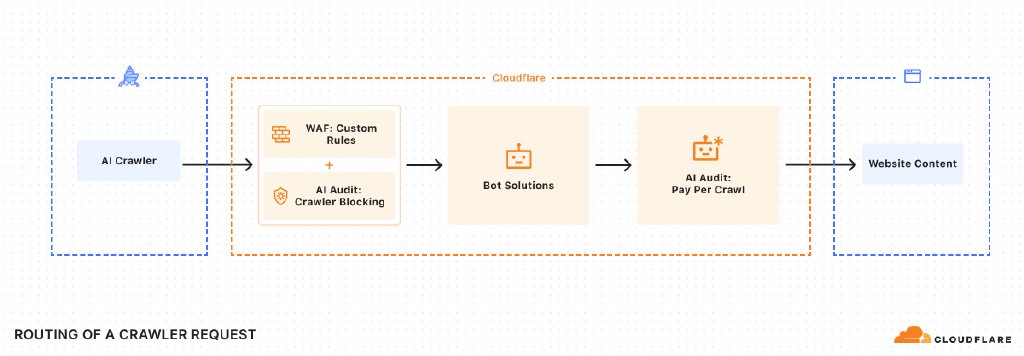
在CloudFlare仪表板中,站点所有者将能够为每个AI搜寻器设置三个访问规则之一:
允许:授予完全访问(HTTP200)。
收费:要求每个请求付款(http402带有价格信息)。
块:拒绝访问(HTTP403),但提示将来可以谈判付款。
就像在内容和生成模型之间引入API一样,信息不仅是自由浮动知识;现在,这是一个可获利的数字资产。
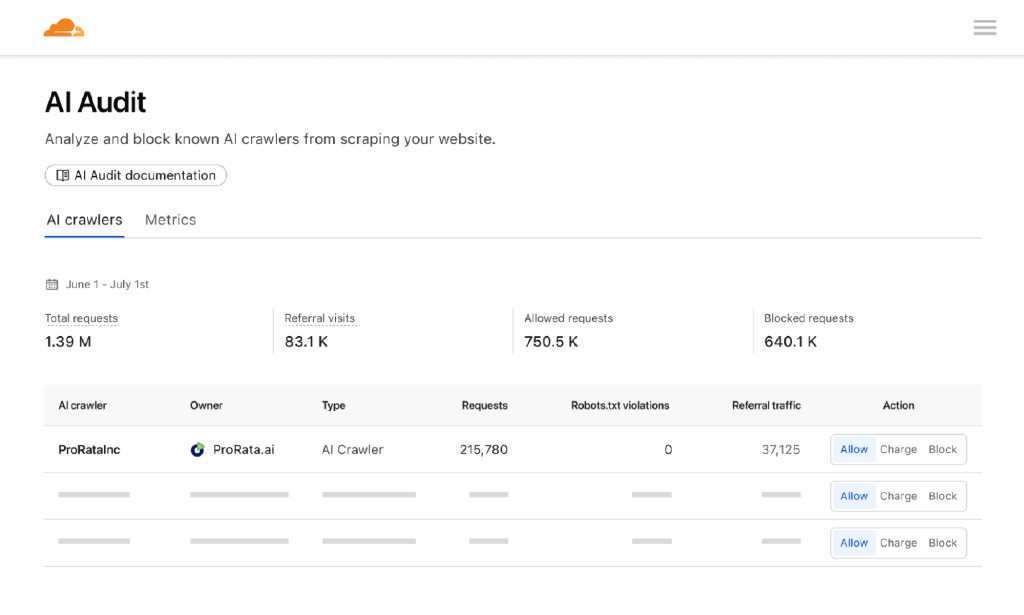
而且让我们清楚:这不是试图振作网络的车库阶段启动。
根据公司数据,CloudFlare为所有网站中的20%以上(包括媒体公司,内容平台,政府和主要品牌)为CDN基础架构提供了动力。
诸如Reddit,Muider,Shopify,Udemy和Guardian之类的网站都通过Cloudflare的网络运行。
这意味着一件简单的事情:如果Cloudflare决定限制访问权限,则可以大规模地进行。
但是比例只是图片的一部分。
Cloudflare还确切知道哪些机器人正在访问这些站点以及多久一次。
Bytespider是由Bondedance(Tiktok的母公司)经营的AI爬行者,是最活跃的,访问了所有受Cloudflare保护的域的40.4%以上。
接下来:来自Openai的GPTBOT,占35.5%,其次是Claudebot,拟人化为11.2%。
有趣的是,尽管GPTBOT是最“主流”,但也是整个网络上最常见的机器人之一。
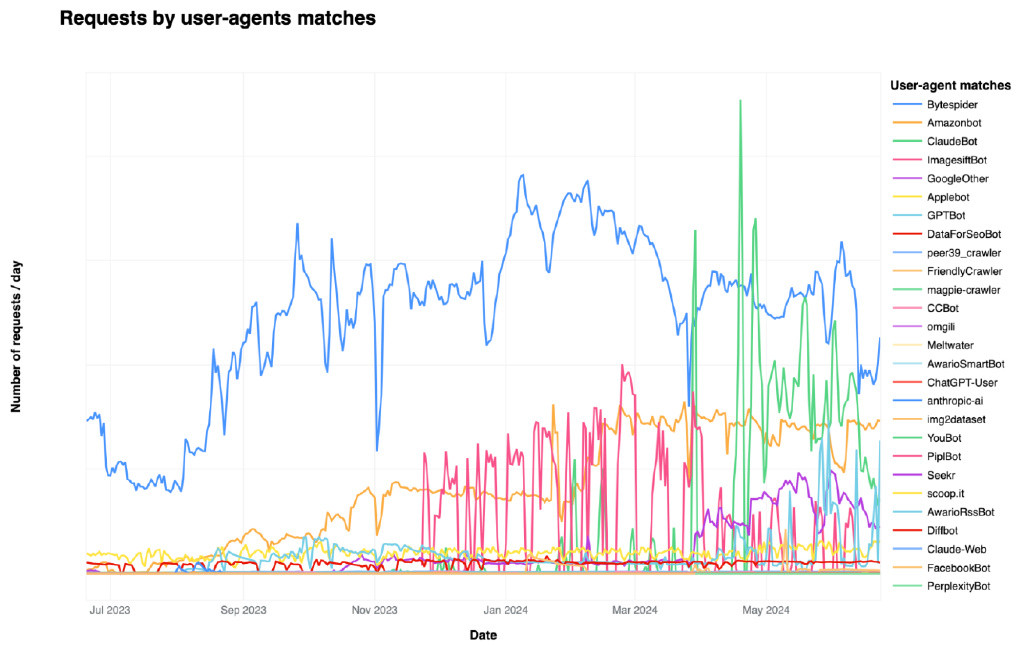
Cloudflare指出,许多发布者甚至都不知道AI爬行者正在如此积极访问他们的网站。这种隐藏刮擦的规模可能远大于大多数人所意识到的。
每次爬行影响SEO将如何支付?
首先,让我们清楚一点:CloudFlare不会默认情况下阻止Bingbot,Googlebot或任何传统的搜索引擎爬网。
但是,默认情况下,它确实阻止了像GPTBOT或Claudebot这样的AI爬网,特别是对于加入该平台的新网站。
站点所有者可以使用CloudFlare的新访问规则来覆盖此设置,并确定允许,阻止或充电的机器人。
该更新专门针对AI模型,来自OpenAI等公司的爬行者以及收集内容以训练或驱动大型语言模型(LLMS)的内容,而不是提供实时搜索结果。
也就是说,CloudFlare首次为发布者提供了阻止或收取传统搜索引擎爬网的选项,这是以前根本不存在的控制水平。
发行商实际上会这样做吗?
可能不是,至少不是大多数。
阻止Google或Bing仍然意味着冒着大量有价值的有机流量的风险,而对于许多人来说,价格太高了。
尽管《华尔街日报》最近报告说,由于AI驱动的搜索经验,出版商流量的下降下降,但Google仍负责当今大多数出版商的流量中很大一部分,通常是30-60%或以上,具体取决于网站。
但这开始改变。
越来越多的主要出版商加入了Cloudflare的PerCrawlInitiative,包括:
时间。
大西洋。
adweek。
BuzzFeed。
财富。
Quora。
堆栈溢出。
WebFlow。
出版物首先报道了这个故事的。
因此,尽管SEO仍然太重要了,对于大多数人来说,第一次说“不”或至少“付款”的权力正式在桌上。
每次爬行影响地理薪水将如何支付?
绝对,比您想象的要深刻。
要了解为什么,让我们以Chatgpt为例。众所周知,ChatGpt的高级版本使用Bing执行实时搜索。
但是在幕后,实际上有两个独立的过程:
模型培训(培训数据)
在模型可以搜索任何内容之前,首先需要培训它。这是LLM学习语言如何运作并建立他们对世界的知识的时候,使用包括文本,代码,图像和信息从公共网络中汲取的信息。
该内容由GPTBOT(OpenAI),Anthropicbot(Anthropic)和Google和Meta操作的类似机器人等专用的AI爬行者收集。您可以在此处阅读有关OpenAI数据收集过程的更多信息。
实时信息检索
训练模型后,它可以通过外部工具从Web获取新的数据,例如Chatgpt的Bing集成。
乍一看,您可能会认为:“如果我的网站没有阻止Bing,Chatgpt仍会在用户搜索时看到它,那么大不了的是什么?”
但这是关键区别:
培训是建立模型对世界的基本理解,其语言,主题,背景和领域专业知识的原因。
实时搜索只是一种补充理解而不是替代它的方式。
这就是每次爬网的薪水开始重要的。
随着越来越多的网站限制对AI爬网的访问,培训过程变得有限,这会产生三个主要影响。
答案质量下降(即使实时搜索)
即使该模型可以通过Bing或Brave“看到”您的网站,如果在培训期间不接触类似材料,它将不知道如何解释或优先考虑您的内容。
对已知来源的内置偏见
模型倾向于偏爱他们在培训期间看到的资源。他们更多地“相信”他们。
如果您的内容不是该过程的一部分,那么您可能会在AI生成的答案中被忽略或较少可见,仅仅是因为该模型无法识别您的音调,格式或权威。
对GEO的长期影响
随着越来越多的网站选择每次爬网薪水并限制访问权限,AI模型可用的总体培训数据变得越来越小。
在培训期间看不到的网站也不会成为模型“心理图”的一部分,即使在实时搜索过程中可以在技术上访问它们。
底线
实时搜索可能仍然起作用,但是如果没有强大的基础,该模型就不知道要寻找什么,如何解释它或您的内容很重要。
地理不仅仅是可见度;这是关于模型是否认识您炒股配资网站皆,信任您并了解您。所有这些始于培训。
嘉汇优配提示:文章来自网络,不代表本站观点。
相关文章

热点资讯
